

A maioria das soluções de Inteligência Artificial funciona na nuvem, o que gera custos, dependência de internet e riscos de privacidade. A IA off-line surge como alternativa para rodar modelos diretamente no computador ou em servidores próprios, garantindo mais autonomia e segurança.
O Ollama se destaca por ser simples, rápido e permitir rodar modelos localmente com poucos comandos. Seja para uso pessoal ou em servidores dedicados, é uma forma prática de explorar IA sem depender de terceiros.
Neste guia rápido, você vai aprender como começar a usar o Ollama em minutos.
Passo a passo com o Ollama
Instalação
Instale o Ollama: https://ollama.com/download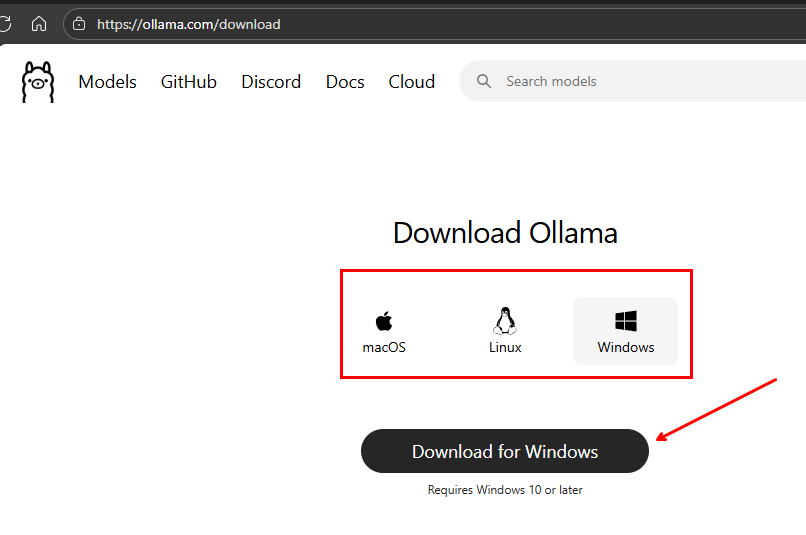
Usando com interface visual
Uma ótima novidade nas versões atuais do Ollama é que ele já instala um programa com interface visual em formato de chat, o que facilita muito o seu uso. Veja: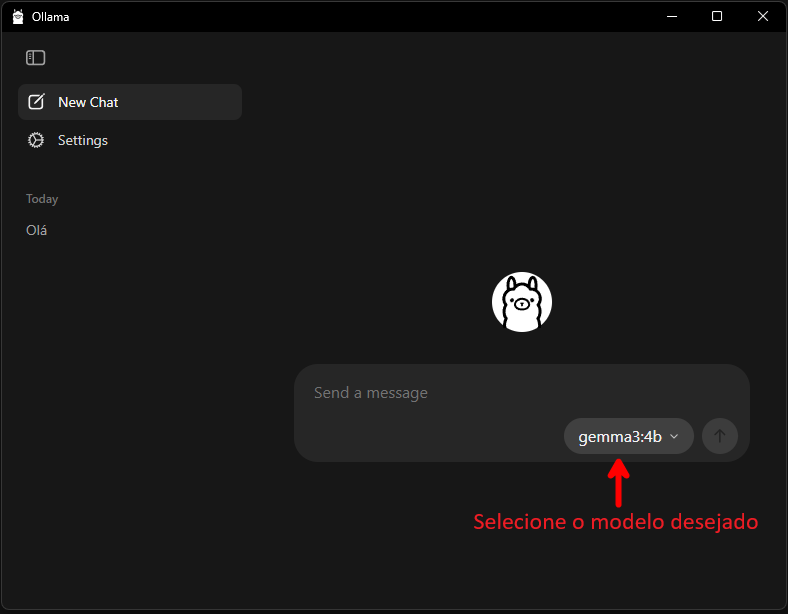
Ao enviar um prompt (pergunta), caso o modelo ainda não tenha sido baixado, o Ollama fará o download automaticamente.
Usando via prompt ou terminal
No site escolha um modelo: https://ollama.com/search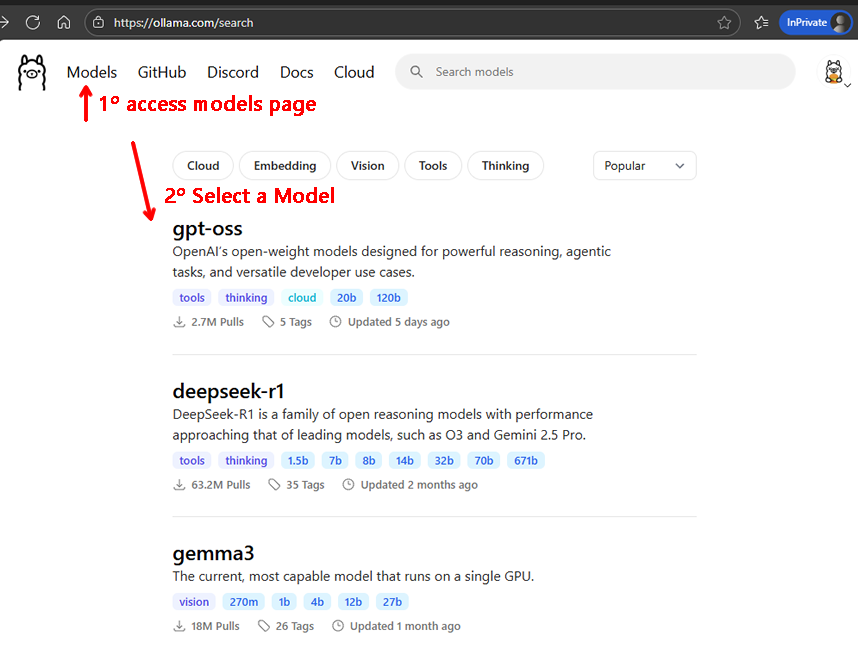
Após selecionar o modelo desejado, clique no ícone indicado na imagem para copiar o comando a ser utilizado: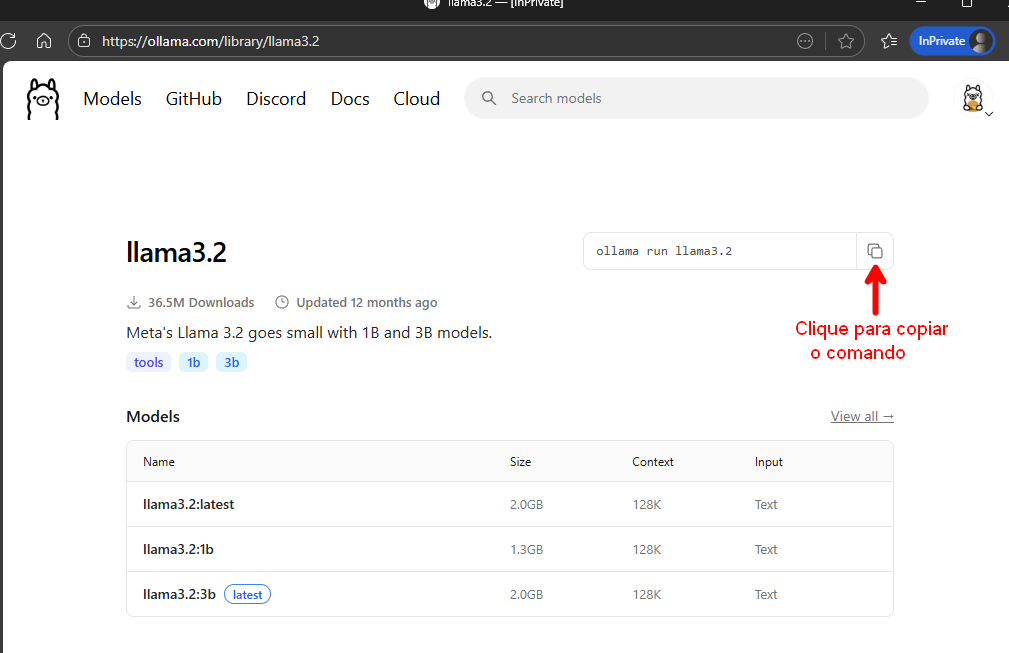
Abra o prompt de comando ou terminal e cole/escreva comando “ollama run <name_model>” e aguarde a conclusão da instalação
Após a instalação, você já pode usar o Ollama off-line diretamente pelo prompt ou terminal. Basta executar: “ollama run <name_model>”
Principais comandos do Ollama
- Ajuda: ollama –help
- Verificar versão: ollama –version
- Listar modelos instalados: ollama list
- Rodar um modelo: ollama run <nome_modelo>
- Baixar um modelo: ollama pull <nome_modelo>
- Remover um modelo: ollama rm <nome_modelo>
- Ver informações de um modelo: ollama show <nome_modelo>
- Parar um modelo em execução: ollama stop <nome_modelo>
- Mostra o processo de modelos em execução: ollama ps
Acessando Ollama via API
Além do uso via terminal ou interface visual, o Ollama também disponibiliza uma API local que pode ser acessada em http://127.0.0.1:11434/api/chat (porta padrão 11434). Para interagir com a IA, utilize o verbo POST enviando no corpo da requisição um JSON no formato:
{
"model": "nome-do-modelo",
"messages": [
{
"role": "user",
"content": "Insira seu prompt com a pergunta desejada"
}
],
"stream": false
}
Assim, você pode integrar o Ollama facilmente a outros sistemas ou aplicações.
Alterando a porta do Ollama
O Ollama, por padrão, roda no endereço 127.0.0.1:11434. Porém, é possível alterar esta porta e isso é feito através da variável de ambiente OLLAMA_HOST.
Exemplo temporário (Windows)
Para iniciar o Ollama na porta 11435 apenas naquela sessão do terminal:
set OLLAMA_HOST=127.0.0.1:11435
ollama serveAssim, o Ollama ficará disponível em 127.0.0.1:11435.
Exemplo permanente (Windows)
Se quiser que essa configuração seja usada sempre, defina a variável OLLAMA_HOST no sistema:
- Vá em Painel de Controle > Sistema > Configurações Avançadas > Variáveis de Ambiente (ou simplesmente digite Variáveis de Ambiente no menu Iniciar do Windows)
- Crie uma variável chamada OLLAMA_HOST
- Defina o valor, por exemplo: 127.0.0.1:11435
- Salve e reinicie o Ollama
Permitir conexões de outros IPs
Para permitir conexões de outros IPs, acesse as configurações do Ollama e marque a opção “Expose Ollama to the network” (Expor o Ollama à rede).

Vídeo de demonstração
IA na Prática 25 – Ollama | IA Offline | Instalação e configuração
E aí, pronto para testar o Ollama e explorar o poder da IA off-line? 🚀
Espero que este guia rápido tenha ajudado você a dar os primeiros passos.
Se ficou alguma dúvida ou se quiser compartilhar sua experiência, deixe um comentário abaixo, vou adorar saber a sua opinião!